简要记录了读取数据文件的各类包。
一. 文本类
1. open
open
(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
读写任意文本,自由度高,对于特定文件,可用其他包快捷读取。
参数说明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式。t文本模式、b二进制、r读、w覆盖写、x写不覆盖、a追加写、+补充读写功能,及其组合
buffering: 设置缓冲,-1: 默认,一般默认4、8KB;0: 无缓冲;1: 行缓冲;>1,设置大小缓存区大小,单位 Byte,IO限制时搜索优化
encoding: 一般使用utf-8,还有ascii、utf*、gb*、iso*等,不可设置非文本编码,如zlib_codec、uu_codec
errors: 报错级别
'strict' 默认值,抛出 UnicodeDecodeError 或 UnicodeEncodeError
'ignore' 忽略无法编解码的字符
'replace' 用替换字符(如 ? 或 \ufffd)替代无法处理的字符
'surrogateescape' 用私有码点(\uDCnn)替代无法处理的字符
'backslashreplace' 用 Python 反斜杠转义序列替换无法处理的字符
'xmlcharrefreplace' 用 XML 字符引用替换(仅用于编码)
'namereplace' 用 \N{...} 格式替换字符名称(仅用于编码)
newline: 区分换行符
一般文本文件 None(默认)
CSV 文件 ''
强制 Unix 风格换行 '\n'
强制 Windows 风格换行 '\r\n'
保留原始换行符 ''
#closefd: 管理文件描述符,多修改于多进程/线程场景
#opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
|
2. csv
csv.reader
(csvfile, dialect=‘excel’, **fmtparams)
读取csv文件,返回list迭代器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| csvfile:"*任何*"支持迭代器的对象,通常是文件对象(用 open() 打开的文件)。
dialect:指定 CSV 格式的方言,默认是 'excel',即 Excel 默认导出的 CSV 格式,可通过csv.register_dialect()自定义。
**fmtparams:可选参数,用于覆盖方言中的某些设置,如分隔符、引用符等。
1. delimiter :指定字段之间的分隔符,默认是逗号 ,。
2. quotechar :指定引用字符,用于包裹包含特殊字符(如分隔符、换行符)的字段,默认是双引号 "。
3. escapechar :指定转义字符,用于转义引用字符或分隔符,默认是 None。
4. doublequote :布尔值,控制是否将两个连续的引用字符视为一个引用字符,默认是 True。
5. skipinitialspace :布尔值,控制是否忽略分隔符后的空格,默认是 False。
6. lineterminator :指定行终止符,仅在写入时有效,读取时会被忽略。
7. quoting :控制引用行为,可选值:
csv.QUOTE_MINIMAL:仅在必要时引用字段(默认)。
csv.QUOTE_ALL:引用所有字段。
csv.QUOTE_NONNUMERIC:引用所有非数字字段。
csv.QUOTE_NONE:不引用任何字段
|
csv.DictReader
(csvfile, fieldnames=None, restkey=None, restval=None, dialect=‘excel’, *args, **kwds)
读取csv文件,返回dict迭代器
1
2
3
4
5
6
| csvfile :"*任何*"支持迭代器的对象
fieldnames :指定列名的列表,默认第一行。
restkey :用于收集多余列的键名,默认忽略。
restval :用于填充缺少列的值,默认None。
dialect :指定 CSV 的格式方言,默认excel,可自定义。
*args, **kwds :用于传递额外的格式化参数,如 delimiter、quotechar 等。
|
3. pandas.read_csv
pandas.read_csv
(filepath_or_buffer, sep=‘, ‘, delimiter=None, header=‘infer’, names=None, index_col=None, usecols=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, date_format=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression=‘infer’, thousands=None, decimal=b’.’, lineterminator=None, quotechar=‘"’, quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors=‘strict’, dialect=None, on_bad_lines=‘error’, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)
读取csv,txt,tsv文件,返回DataFrame对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| filepath_or_buffer :文件路径或文件对象。
sep :指定字段之间的分隔符,默认是逗号 ,。
delimiter :指定字段之间的分隔符,默认是 None,与 sep 互斥。
header :指定列名所在的行,默认是 'infer',即自动推断。可以指定行号,如 0 表示第一行。
names :指定列名列表,默认是 None,即使用文件中的列名。
index_col :指定用作索引的列,默认是 None,即不使用任何列作为索引。
usecols :指定要读取的列,默认是 None,即读取所有列。
dtype :指定列的数据类型,默认是 None,即自动推断。
engine :指定解析引擎,默认是 'c',即 C 引擎。可选 'python'。
converters :指定列的转换函数,默认是 None。
true_values :指定表示 True 的值,默认是 None。
false_values :指定表示 False 的值,默认是 None。
na_values :指定表示缺失值的字符串,默认是 None。
keep_default_na :是否保留默认的缺失值,默认是 True。
skipinitialspace :忽略分隔符后的空格,默认是 False。
skiprows :指定要跳过的行,默认是 None,即不跳过任何行。可以指定行号,如 [0, 1] 表示跳过第一行和第二行。
skipfooter :指定要跳过的行数,默认是 0,即不跳过任何行。
nrows :指定要读取的行数,默认是 None,即读取所有行。
na_filter :是否过滤缺失值,默认是 True。
skip_blank_lines :是否跳过空行,默认是 True。
parse_dates :指定要解析为日期的列,默认是 False。
infer_datetime_format :是否自动推断日期格式,默认是 False。
comment :指定注释字符,默认是 None,即不忽略注释行。
encoding :指定文件编码,默认是 None,即自动推断。
encoding_errors :指定编码错误处理方式,默认是 'strict'。
low_memory :是否使用低内存模式,默认是 True。
memory_map :是否使用内存映射,默认是 False。
float_precision :指定浮点数精度,默认是 None。
storage_options :指定存储选项,默认是 None。
|
4. pandas
pandas.read_excel
(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, date_format=None, thousands=None, comment=None, skipfooter=0, storage_options=None, dtype_backend=‘numpy’)
读取xlsx,xlsm,xlsb文件,返回DataFrame对象
xlsx内容是二进制压缩文件,可解压,含有多个xml文件
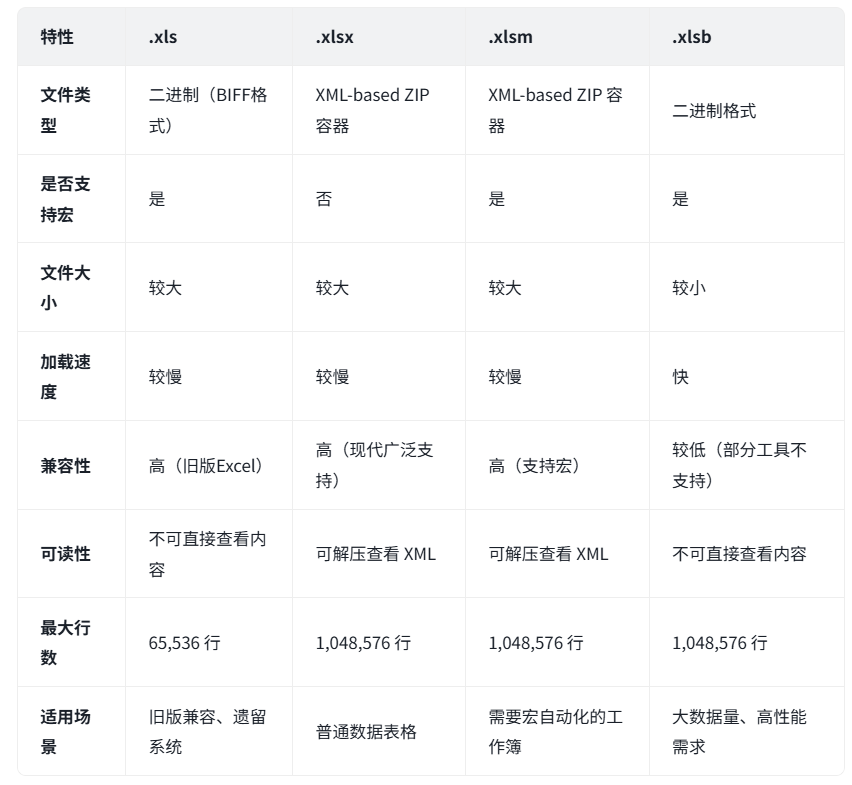
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| io :文件路径或文件对象。
sheet_name :指定要读取的工作表,默认是 0,即第一个工作表。可以指定工作表名或索引。
header :指定列名所在的行,默认是 0,即第一行。可以指定行号,如 1 表示第二行。
names :指定列名列表,默认是 None,即使用文件中的列名。
index_col :指定用作索引的列,默认是 None,即不使用任何列作为索引。
usecols :指定要读取的列,默认是 None,即读取所有列。
dtype :指定列的数据类型,默认是 None,即自动推断。
engine :指定解析引擎,默认是 None,即自动推断。
converters :指定列的转换函数,默认是 None。
true_values :指定表示 True 的值,默认是 None。
false_values :指定表示 False 的值,默认是 None。
skiprows :指定要跳过的行,默认是 None,即不跳过任何行。可以指定行号,如 [0, 1] 表示跳过第一行和第二行。
nrows :指定要读取的行数,默认是 None,即读取所有行。
na_values :指定表示缺失值的字符串,默认是 None。
keep_default_na :是否保留默认的缺失值,默认是 True。
na_filter :是否过滤缺失值,默认是 True。
|
5. openpyxl
openpyxl.load_workbook
(filename, read_only=False, keep_vba=False, data_only=False, keep_links=True, storage_options=None)
读取excel文件,返回Workbook对象
1
2
3
4
5
| filename :文件路径或文件对象。
read_only :是否以只读模式打开,默认是 False。
keep_vba :是否保留 VBA 宏,默认是 False。
data_only :是否只读取单元格的值,默认是 False。
keep_links :是否保留超链接,默认是 True。
|
6.xlrd
xlrd.open_workbook
(filename, logfile=None, verbosity=0, use_mmap=1, file_contents=None, encoding_override=None, formatting_info=False, on_demand=False, ragged_rows=False)
读取xls文件,返回Book对象
1
2
3
4
5
6
7
8
9
| filename :文件路径或文件对象。
logfile :日志文件路径,默认是 None。
verbosity :日志级别,默认是 0。
use_mmap :是否使用内存映射,默认是 1。
file_contents :文件内容,默认是 None。
encoding_override :文件编码,默认是 None。
formatting_info :是否保留格式信息,默认是 False。
on_demand :是否按需加载,默认是 False。
ragged_rows :是否允许不规则的行,默认是 False。
|
7. json
json.load
(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
1
2
3
4
5
6
7
8
9
| fp :一个支持 .read() 方法的文件对象
* :指定后续参数为关键字参数
cls :自定义 JSON 解码器的类,默认使用 json.JSONDecoder。如果你需要自定义解码逻辑,可以继承 JSONDecoder 并传入。
object_hook :≈数据读取后简单的"预处理",参数为dict格式。
parse_float :自定义浮点数解析函数。默认是 float。你可以替换为 decimal.Decimal 以提高精度。
parse_int :自定义整数解析函数。默认是 int。你可以替换为自定义函数,或者使用其他库如 numpy 的 int64。
parse_constant :一个函数,用于解析 JSON 中的常量:-Infinity, Infinity, NaN。可自定义常量解析函数。
object_pairs_hook :一个函数,用于处理 JSON 对象的键值对。默认是 dict。你可以替换为自定义函数,或者使用其他库如 collections.OrderedDict。
**kw :其他传递给 JSONDecoder 的参数。
|
json.loads
(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
1
2
| s :一个 JSON 格式的字符串
其他同上json.load()
|
8. yaml
yaml.load
(stream, Loader=yaml.Loader)
用于将 YAML 字符串或文件流解析为 Python dict对象。简单的load存在安全性问题,会执行输入中的代码
1
2
3
4
5
6
7
8
9
| stream :字符串、字节流或文件对象
Loader :指定加载器,默认是 yaml.Loader。你可以替换为其他加载器,如 yaml.FullLoader。
Loader的区别在与对数据结构解析的复杂性以及安全性,二者基本不可兼得
| Loader | 安全性 | 是否支持 Python 对象 | 适用场景 |
Loader 不安全 是 完全信任的数据
SafeLoader 安全 否 用户输入、外部数据
FullLoader ️ 中等 是 复杂结构+一定安全性
UnsafeLoader 不安全 是 明确需要解析 Python 对象
BaseLoader 安全 否 仅解析结构,不转换类型
|
yaml.load_all(stream, Loader)
解析包含多个 YAML 文档的流(stream)的函数,需指定Loader
yaml文件中以"—"为文档分割线
yaml.safe_load(stream)
== load(stream, Loader=yaml.SafeLoader)
yaml.safe_load_all(stream)
== load_all(stream, Loader=yaml.SafeLoader)
yaml.unsafe_load(stream)
== load(stream, Loader=yaml.UnsafeLoader)
yaml.unsafe_load_all(stream)
== load_all(stream, Loader=yaml.UnsafeLoader)
yaml.full_load(stream)
== load(stream, Loader=yaml.FullLoader)
yaml.full_load_all(stream)
== load_all(stream, Loader=yaml.FullLoader)
9. xml.etree.ElementTree
xml.etree.ElementTree.parse
(source, parser=None)
解析 XML 文件并返回一个 ElementTree 对象。
1
2
| source 可以是文件名、文件对象或文件路径。
parser 是可选的解析器对象,默认XMLParser。
|
xml.etree.ElementTree.fromstring
(text, parser=None)
解析 XML 字符串并返回一个 Element 对象。
xml.etree.ElementTree.iterparse
(source, events=None, parser=None)
增量解析:
不会一次性加载整个 XML 文件,而是逐块读取并解析,适合处理大文件。
返回一个迭代器,每次生成一个 (event, elem) 元组。
事件驱动:
可以监听解析过程中的事件(如元素开始、结束、命名空间声明等)。
常见事件:
“start”:元素开始解析时触发。
“end”:元素解析完成时触发(此时可以访问元素的完整内容)。
“start-ns”:命名空间开始声明时触发。
“end-ns”:命名空间结束声明时触发。
内存优化:
解析完成后,建议手动调用 elem.clear() 清理已处理的元素,避免内存泄漏。
10. configparser
configparser.ConfigParser().read
(filenames, encoding=None)
读取配置文件,返回一个字典,键为section,值为section中的键值对
1
2
| filenames :一个文件名列表,ConfigParser 会按顺序读取这些文件,后面的文件会覆盖前面的同名配置。
encoding :指定文件的编码格式,默认为 None,即使用系统默认编码。
|
二. (反)序列化文件
11. pickle
pickle.load
(file, *, fix_imports=True, encoding=‘ASCII’, errors=‘strict’, buffers=None)
从文件中读取并反序列化对象。
1
2
3
4
5
| file :一个支持 .read() 方法的文件对象,通常是通过 open() 打开的文件。
fix_imports :布尔值,默认为 True。如果为 True,pickle 将尝试修复 Python 2 和 Python 3 之间的导入差异。
encoding :指定字符串的编码格式,默认为 'ASCII'。 ASCII latin1 bytes
errors :指定字符串编码错误的处理方式,默认为 'strict'。strict ignore replace
buffers :一个可迭代对象,用于提供原始二进制数据。如果提供,pickle 将直接从该对象读取数据,而不是从文件中读取。
|
三. 二进制文件
12. numpy
numpy.loadtxt
(fname, dtype=float, comments=‘#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding=‘bytes’, max_rows=None)
读取文本文件并返回一个 NumPy 数组。
1
2
3
4
5
6
7
8
9
10
11
| fname :文件名或文件对象。
dtype :数据类型,默认为 float。
comments :注释字符,默认为 '#'。
delimiter :分隔符,默认为 None,即使用默认分隔符(通常是空格或制表符)。
converters :一个字典,用于将特定列转换为特定类型。
skiprows :跳过的行数,默认为 0。有表头应设置为1忽略
usecols :要读取的列,默认为 None,即读取所有列。与pandas.read_csv()中的usecols不同,此处使用数字
unpack :如果为 True,则将每列拆分为单独的数组(类似 zip(*data))。。
ndmin :返回数组的最小维数,默认为 0。
encoding :文件的编码格式,默认为 'bytes'。
max_rows :要读取的最大行数,默认为 None,即读取所有行。
|
numpy.load
(fname, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding=‘ASCII’, errors=‘strict’)
从文件中读取并返回一个 NumPy 数组。
1
2
3
4
5
6
| fname :文件名或文件对象。
mmap_mode :内存映射模式,默认为 None。如果为 None,则不使用内存映射。
allow_pickle :是否允许加载 pickle 格式的数据,默认为 False。
fix_imports :是否修复 Python 2 和 Python 3 之间的导入差异,默认为 True。
encoding :字符串的编码格式,默认为 'ASCII'。
errors :字符串编码错误的处理方式,默认为 'strict'。
|
四. 图片文件
13. PIL.Image
Image.open
(fp, mode=‘r’, formats=None)
打开并返回一个 Image 对象。
1
2
3
| fp :一个文件名、文件对象或类似文件的对象。
mode :打开文件的模式,默认且仅为 'r'(读取)。
formats :一个可选的格式列表,用于指定支持的图像格式。
|
五. 压缩文件
14. tarfile
tarfile.open
(name=None, mode=‘r’, fileobj=None, bufsize=10240, **kwargs)
打开tar, tar.gz压缩文件并返回一个 TarFile 对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| name :文件名或文件对象。
mode :打开文件的模式,默认为 'r'(读取)。
‘r’ 读取未压缩的 tar 文件
‘r:gz’ 读取 gzip 压缩的 tar 文件
‘r:bz2’ 读取 bzip2 压缩的 tar 文件
‘r:xz’ 读取 xz 压缩的 tar 文件
‘w’ 写入未压缩的 tar 文件
‘w:gz’ 写入 gzip 压缩的 tar 文件
‘w:bz2’ 写入 bzip2 压缩的 tar 文件
‘w:xz’ 写入 xz 压缩的 tar 文件
‘a’ 追加内容到现有 tar 文件
fileobj :一个已打开的文件对象,默认为 None。
bufsize :缓冲区大小,默认为 10240。
**kwargs :其他参数,如压缩格式等。
|
15. gzip
gzip.open
(fileobj, mode=‘rb’, compresslevel=9)
打开gz压缩文件并返回一个 GzipFile 对象。
1
2
3
4
5
6
7
8
9
10
11
| fileobj :一个文件对象,用于读取或写入 gzip 压缩的数据。
mode :打开文件的模式,默认为 'rb'(读取二进制)。
‘rb’ 二进制读模式(默认)
‘wb’ 二进制写模式
‘rt’ 文本读模式
‘wt’ 文本写模式
‘ab’ 二进制追加模式
‘at’ 文本追加模式
compresslevel :压缩级别,默认为 9(最高压缩级别)。
encoding :指定文本编码,默认为 'utf-8'。
errors :指定文本编码错误的处理方式,默认为 'strict'。
|
15. zipfile
zipfile.ZipFile
(name, mode=‘r’, compression=zipfile.ZIP_STORED, allowZip64=True, compresslevel=None)
打开zip压缩文件并返回一个 ZipFile 对象。
1
2
3
4
5
6
7
8
| name :文件名或文件对象。
mode :打开文件的模式,默认为 'r'(读取)。
‘r’ 读取已压缩的 zip 文件
‘w’ 写入新的 zip 文件
‘a’ 追加内容到现有 zip 文件
compression :压缩格式,默认为 ZIP_STORED(不压缩)。
allowZip64 :是否允许使用 ZIP64 格式,默认为 True。
compresslevel :压缩级别,默认为 None,即使用默认级别。
|
六. 大型数据文件
16. h5py
h5py.File
(name, mode=‘r’, driver=None, libver=None, userblock_size=None, swmr=False, rdcc_nbytes=None, rdcc_nslots=None, rdcc_w0=None, track_order=None, **kwds)
打开 h5 文件并返回一个 File 对象。keras2系列的tensorflow保存数据和模型为.h5文件,而keras3保存为.keras文件
1
2
3
4
5
6
7
8
9
10
11
| name :文件名或文件对象。
mode :打开文件的模式,默认为 'r'(读取)。
driver :驱动程序,默认为 None。
libver :库版本,默认为 None。
userblock_size :用户块大小,默认为 None。
swmr :是否启用共享写模式读取,默认为 False。
rdcc_nbytes :RDCache 缓冲区大小,默认为 None。
rdcc_nslots :RDCache 插槽数,默认为 None。
rdcc_w0 :RDCache 写入比例,默认为 None。
track_order :是否跟踪数据顺序,默认为 None。
**kwds :其他参数。
|
17. LMDB
lmdb.open
(path, map_size=2**32, max_readers=1000, readonly=False, meminit=True, map_async=False, mode=0o660, lock=True, readahead=True, metasync=True, sync=True, map_size_limit=None)
打开 LMDB 数据库并返回一个 Environment 对象。
1
2
3
4
5
6
7
8
9
10
11
12
| path :数据库路径。
map_size :数据库大小,默认为 4GB。
max_readers :最大读取器数量,默认为 1000。
readonly :是否以只读模式打开数据库,默认为 False。
meminit :是否初始化内存,默认为 True。
map_async :是否异步映射数据库,默认为 False。
mode :文件权限,默认为 0o660。
lock :是否使用文件锁,默认为 True。
readahead :是否预读数据,默认为 True。
metasync :是否同步元数据,默认为 True。
sync :是否同步数据,默认为 True。
map_size_limit :数据库大小限制,默认为 None。
|
18. pyarrow
pyarrow.csv.read_csv
(source, read_options=None, parse_options=None, **kwargs)
从 CSV 文件中读取数据并返回一个 Table 对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| source :CSV 文件路径或文件对象。
read_options :一个 ReadOptions 对象,用于指定读取选项。
pyarrow.csv.ReadOptions(
use_threads=True,
block_size=256*1024*1024,
encoding='utf8',
skip_rows=1,
column_names=['id', 'name', 'value']
autogenerate_column_names=False
)
parse_options :一个 ParseOptions 对象,用于指定解析选项。
pyarrow.csv.ParseOptions(
delimiter='|',
quote_char="'",
double_quote=False,
newlines_in_values=False
)
**kwargs :其他参数,如列名等。
|
pyarrow.parquet.read_table
(source, columns=None, use_threads=True, read_dictionary=False, filters=None, metadata=None, chunk_size=None, **kwargs)
从 Parquet 文件中读取数据并返回一个 Table 对象。
1
2
3
4
5
6
7
| source :Parquet 文件路径或文件对象。
columns :要读取的列名列表,默认为 None,即读取所有列。
use_threads :是否使用多线程,默认为 True。
read_dictionary :是否读取字典编码的列,默认为 False。
filters :一个 Filter 对象,用于指定过滤条件。
metadata :一个 ParquetMetadata 对象,用于指定元数据。
**kwargs :其他参数。
|
七. 数据库
MySQL
mysql.connector.connect
(host=None, user=None, password=None, database=None, port=3306, ssl_ca=None, ssl_cert=None, ssl_key=None, ssl_disabled=False, use_unicode=True, charset=‘utf8mb4’, collation=‘utf8mb4_unicode_ci’, autocommit=False, buffered=True, local_infile=False, connect_timeout=10, init_command=None, client_flag=0, conv=py3conv, auth_plugin=None, **kwargs)
连接 MySQL 数据库并返回一个 MySQLConnection 对象。
尝试连接SQLExpress2022本地数据库,连接失败,以下参数仅作参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| host :数据库主机名,默认为 None。
user :数据库用户名,默认为 None。
password :数据库密码,默认为 None。
database :数据库名,默认为 None。
port :数据库端口号,默认为 3306。
ssl_ca :SSL 证书颁发机构文件路径,默认为 None。
ssl_cert :SSL 证书文件路径,默认为 None。
ssl_key :SSL 密钥文件路径,默认为 None。
ssl_disabled :是否禁用 SSL,默认为 False。
use_unicode :是否使用 Unicode,默认为 True。
charset :字符集,默认为 'utf8mb4'。
collation :排序规则,默认为 'utf8mb4_unicode_ci'。
autocommit :是否自动提交事务,默认为 False。
buffered :是否使用缓冲区,默认为 True。
local_infile :是否允许本地文件加载,默认为 False。
connect_timeout :连接超时时间,默认为 10 秒。
init_command :初始化命令,默认为 None。
client_flag :客户端标志,默认为 0。
conv :转换函数,默认为 py3conv。
auth_plugin :认证插件,默认为 None。
**kwargs :其他参数。
|
PostgreSQL
psycopg2.connect
(dsn=None, connection_factory=None, cursor_factory=None, transaction_factory=None, async=False, **kwargs)
连接 PostgreSQL 数据库并返回一个 connection 对象。
1
2
| dsn :连接字符串,格式为 'dbname=数据库名 user=用户名 password=密码 host=主机名 port=端口号',默认为 None。
也可将dsn分开
|
SQLite
sqlite3.connect
Oracle
cx_Oracle.connect
SQL Server
pymssql.connect
MongoDB
pymongo.MongoClient
Redis
redis.Redis
SQLAlchemy
sqlalchemy.create_engine
Django ORM